在此示例中,我将使用在Reddit上的/ r / opendirectories中找到的打开目录。这是找到可笑内容的可下载内容的好地方。从那里,我设法找到一个充满声音效果的打开目录。让我们来看看一个对动物和鸟类有声音效果的东西(此链接在您到达之前可能已经失效,因此下面的屏幕截图)。

We是ho积者,我们想要全部。下一步是转到网站站长工具包的链接提取器。这个独特的小工具将提取您推送的任何网站的链接和图像。让我们在此处复制并粘贴打开目录的URL。由于它们是链接,因此我们提取的是HREF,而不是IMG。 IMG将用于提取图像。这些结果应显示如下。
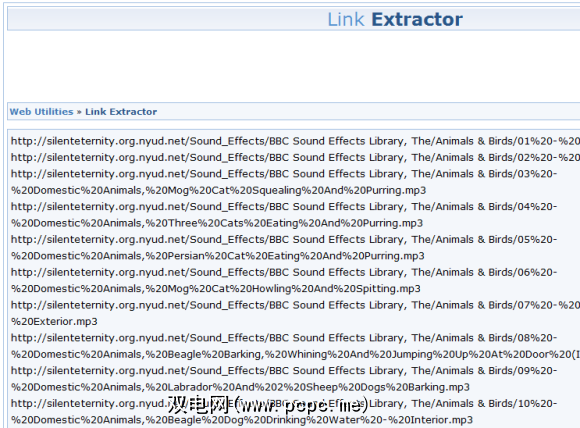
复制所有结果,最后一个除外。最后一个是父目录链接,它基本上是目录中的一个文件夹。对于从许多打开的目录下载的任何人,您总是想排除最后的结果。即使包含它,您也只下载一个HTML网页,所以没什么大不了的。确保将结果复制到剪贴板。
下一步是下载JDownloader并使其运行。
现在让我们选择要将文件保存到的位置。点击设置标签,您应该会看到以下内容。
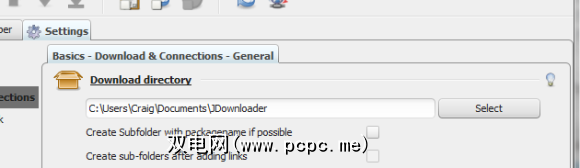
选择目录后,点击 Linkgrabber 标签。 Linkgrabber基本上是JDownloader的内置系统,用于检查链接的有效性。这样,您将不会尝试下载404页或不存在的文件。在您获取所需文件之间是一个很好的中间人。在此窗口的左下方附近,单击添加URL。。您应该会看到以下内容。
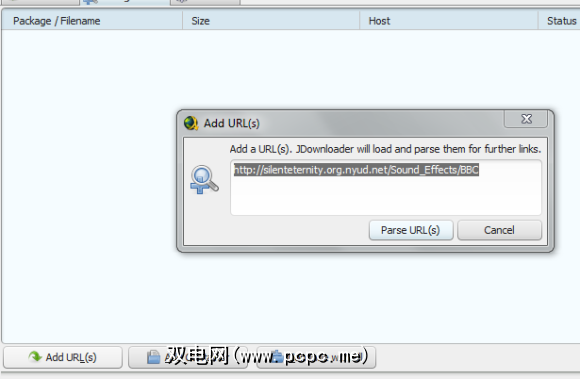
JDownloader尝试提取我们从您复制的URL列表剪贴板,但由于某种原因,应用程序似乎无法正确处理带空格的URL。链接仍然不能包含空格。
现在让我们打开记事本。粘贴您的URL列表。从编辑菜单中,单击替换...。在查找内容:字段中,您要放置一个空格。在替换为字段中,您要输入“%20"(不带引号)。 %20是空格的十六进制值。然后点击全部替换。它将用十六进制值替换所有空格,并且列表中会显示很多空格。不用担心,这意味着它可以正常工作(对于链接中没有空格的网站,您无需在此过程中包括此步骤,这是99%的情况)。
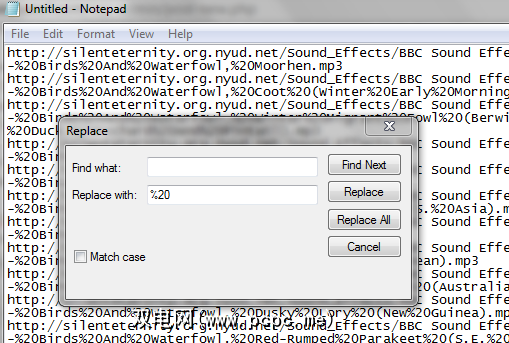
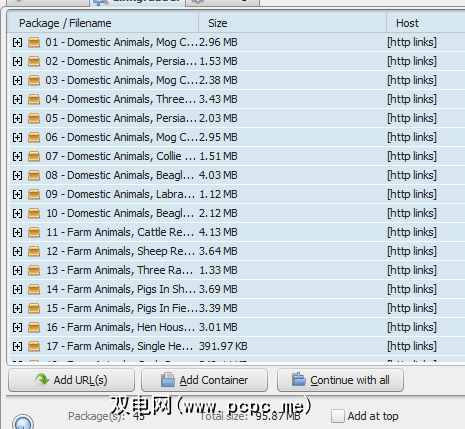
现在我们想要复制该网址列表。删除JDownloader列表中的单行,然后粘贴我们的新列表。然后,JDownloader继续检查列表中的每个文件,并为您提供总的下载大小。
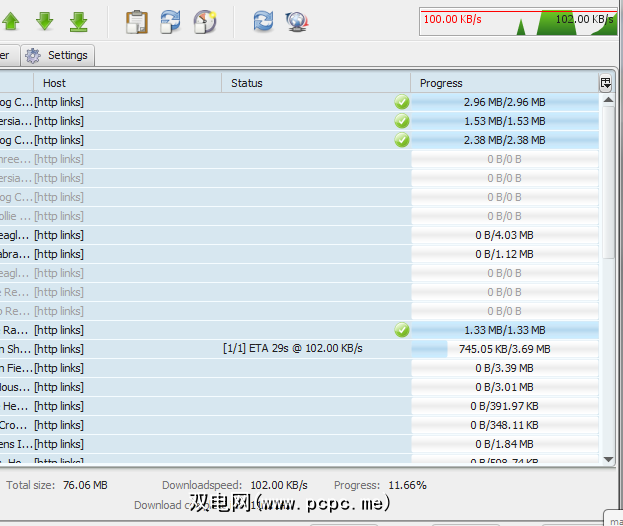
现在,单击顶部的播放按钮开始下载。您将自动切换到下载标签,并且可以监视下载进度。您的文件正在下载!
请记住,使用链接提取器可以提取HREF或IMG。如果您在要保存图像的页面,论坛主题或其他网站上有一个特定的页面,则可以使用完全相同的过程。
如果您需要任何帮助或对这种小方法有其他疑问,请随时在评论中添加一行。 JDownloader适用于更高级的用户(我认为),进一步的无辅助配置可能会有些棘手。我在这里为您提供帮助。