
乔尔·李(Joel Lee)在2017年10月10日更新的文章
对于许多人来说,互联网是Google 。这是寻找新站点的起点,可以说是自互联网本身以来最重要的发明。没有搜索引擎,大众将无法访问新的Web内容。
但是您知道搜索引擎如何工作吗?每个搜索引擎都有三个主要功能:爬行(发现内容) ),建立索引(以跟踪和存储内容)和检索(以在用户查询搜索引擎时获取相关内容)。
抓取
抓取是一切开始的地方:收购网站数据。
这涉及扫描网站并收集有关每个页面的详细信息:标题,图像,关键字,其他链接的页面等。不同的搜寻器也可能会寻找不同的详细信息,例如页面布局,
但是网站是如何爬网的?一个自动漫游器(称为“蜘蛛")访问页面的速度最快可能的情况下,使用页面链接来查找下一步。即使在最早的日子里,谷歌的蜘蛛每秒也可以读取数百页。如今,它已经成千上万了。
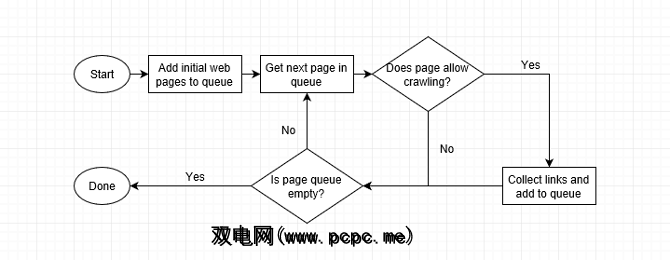
当网络爬虫访问页面时,它会收集页面上的每个链接,并将它们添加到要访问的下一页列表中。它会转到其列表的下一页,收集该页上的链接,然后重复。网络搜寻器还会不时地重新访问过去的页面,以查看是否发生了任何更改。
这意味着从索引站点链接的任何站点最终都将被爬行。有些网站被更频繁地爬网,而有些则被爬得更深,但是如果网站的页面层次结构太复杂,有时爬网程序可能会放弃。
一种理解网络爬网程序如何工作的方式是要自己建立一个。我们已经编写了有关使用PHP创建基本的网络搜寻器的教程,因此请检查一下您是否有任何编程经验。

请注意,页面可以标记为“ noindex",就像要求搜索引擎跳过其索引。互联网的未编制索引的部分称为“深层网络")。
建立索引
建立索引是指对爬网中的数据进行处理并将其放置在数据库中时。
想象一下,列出所有您拥有的书,他们的出版商,他们的作者,他们的体裁,他们的页数等的列表。爬网是当您梳理每本书时,而索引是将它们记录到列表中时。<
现在想像它不仅是一个装满书籍的房间,而且是世界上每个图书馆。这是Google的小规模版本,它将所有这些数据存储在庞大的空间中拥有数千PB的驱动器的数据中心。搜索引擎处理您的搜索查询并返回与您查询最相关的页面。
大多数搜索引擎通过其检索方法来区分自己:它们使用不同的租借标准,以选择最适合您要查找的页面的页面。这就是Google和Bing之间搜索结果不同的原因,以及Wolfram Alpha如此独特的原因。
排名算法会检查您的搜索查询中是否有数十亿页面,从而确定每个用户的相关性。由于其复杂性,公司将其排名算法作为已获专利的行业秘密加以保护。更好的算法可以带来更好的搜索体验。
他们也不希望网络创建者玩这个系统,并不公平地爬上搜索结果的顶部。如果找到了搜索引擎的内部方法,那么各种各样的人肯定会利用这种知识,从而损害像您和我这样的搜索者。

搜索引擎的利用是
最初,搜索引擎根据关键字在页面上出现的频率对网站进行排名,从而导致“关键字塞满",即在页面上充斥大量关键字,这毫无用处。
然后出现了链接重要性的概念:搜索引擎重视具有大量传入链接的网站,因为他们将网站的受欢迎程度视为相关性。但是,这导致了整个网络上的链接垃圾邮件。如今,搜索引擎根据链接站点的“权限"对链接进行加权。搜索引擎对政府机构链接的重视程度要高于链接目录中的链接。
如今,排名算法比以往任何时候都更加神秘,“搜索引擎优化"已不再那么重要。现在,高质量的内容和出色的用户体验可以使搜索引擎获得良好的排名。
搜索引擎的下一步是什么?
嗯,现在有一个有趣的问题。答案是“语义":页面内容的含义。您可以在我们的语义标记概述及其未来影响的概述中了解更多信息。
但这是要点。
现在,您可以搜索“无麸质Cookie"但结果可能会返回不含麸质饼干的配方。相反,您可能会找到常规的Cookie食谱,上面写着“此食谱不是无麸质的。"它具有正确的关键字,但含义不正确。
借助语义,您可以搜索cookie食谱,然后将其删除某些成分:面粉,坚果等。您还可以将结果范围缩小到仅准备时间少于30分钟且评分为4/5或更高的食谱。 那会很棒,对吗?这就是我们要去的地方!
仍然对搜索引擎的工作方式感到困惑吗?查看Google如何解释该过程:
如果您发现这个有趣的地方,则可能还想了解 image 搜索引擎的工作原理。
图片来源:prykhodov / Depositphotos
标签: Google Analytics(分析) Google搜索 网络搜索







