
您是否相信某个东西一旦在Internet上发布就会永远发布?好吧,今天我们要消除这个神话。
事实是,在许多情况下,从互联网根除信息是很有可能的。当然,如果您搜索Wayback Machine,会有记录的网页被删除,对吗?是的,绝对。在Wayback Machine上,记录了许多年前的网页-由于该网页已不存在,因此您无法通过Google搜索找到这些网页。有人删除了它,或者网站被关闭了。
所以,没有任何解决方法,对吧?信息将永远刻在互联网的石头上,有几代人可以看到吗?嗯,不完全是这样。
事实是,虽然可能很难或不可能清除从一个新闻网站或博客扩散到另一个网站(如病毒)的主要新闻报道,但实际上很容易从所有存在的记录中完全清除一个网页或多个网页-删除搜索引擎和Wayback Machine的页面。当然有一个问题,但是我们会解决。
从网上删除博客页面的3种方法
第一种方法是大多数网站所有者使用的方法,因为他们没有更好的了解-只需删除网页即可。发生这种情况可能是因为您意识到自己的网站上存在重复的内容,或者因为您不想在搜索结果中显示页面。
仅删除页面
从网站上完全删除页面的问题是,由于您已经在网上建立了页面,因此可能存在您自己站点的链接以及其他站点到该特定页面的外部链接。当您删除它时,Google会立即将您的页面识别为丢失的页面。
因此,在删除页面时,您不仅为自己创建了“未找到"抓取错误的问题,而且您还为链接到该页面的任何人造成了问题。通常,如果您使用类似Google的自定义404代码之类的内容来为用户提供有用的建议或替代方法,那么从这些外部链接之一访问您网站的用户将看到您的404页面,这不是主要问题。但是,您会认为,可以有更优雅的方法从搜索结果中删除页面,而无需为现有的传入链接启动所有404代码,对吗?
嗯,有。
首先,您应该了解,如果您要从Google搜索结果中删除的网页不是您自己网站中的页面,那么您出局了除非有法律原因,或者该网站未经您的允许在网上发布了您的个人信息,否则运气不佳。如果是这种情况,请使用Google的删除问题排查工具提交请求,以从搜索结果中删除该页面。如果您有一个有效的案例,那么删除该页面可能会找到一些成功的方法-当然,按照我在2009年介绍的操作方法,与网站所有者联系可以取得更大的成功。
现在,如果您要从搜索结果中删除的页面位于您自己的网站上,很幸运。您所需要做的就是创建一个 robots.txt 文件,并确保您已禁止在搜索结果中使用不需要的特定页面,或者禁止使用包含您所包含内容的整个目录不想索引。这就是阻止单个页面的样子。
User-agent: *Disallow: /my-deleted-article-that-i-want-removed.html
您可以按照以下步骤阻止bot抓取您网站的整个目录。
User-agent: *Disallow: /content-about-personal-stuff/
Google有一个出色的支持页面,可以帮助您创建一个robots.txt文件(如果您以前从未创建过)。正如我最近在一篇文章中所述,关于构建联合交易的内容中所解释的那样,这种方法非常有效,以使它们不会伤害您(要求联合合作伙伴禁止对其联合页面进行索引)。一旦我自己的联合伙伴同意这样做,那么我博客中重复内容的页面就会从搜索列表中完全消失。

只有主网站位于列出我们标题的页面的第三位,但我的博客现在同时列在第一和第二位;如果更高权限的网站保留了重复页面的索引,这几乎是不可能的。
许多人没有意识到,这也可以通过Internet Archive(Wayback Machine)来完成也一样这是您需要添加到robots.txt文件中以使其实现的行。
User-agent: ia_archiverDisallow: /sample-category/
在此示例中,我告诉Internet存档删除我网站上sample-category子目录中的所有内容来自Wayback Machine。 Internet存档在其排除帮助页面上说明了如何执行此操作。他们在这里也解释说:“互联网档案馆不希望提供对作者不希望收集其资料的网站或其他互联网文档的访问。"
这与通常的情况相反,我们坚信,发布到互联网上的所有内容都会被永久保存在档案库中。不会-拥有内容的网站管理员可以使用robots.txt方法专门从存档中删除内容。
删除带有元标记的单个页面
如果您只有一个很少要从Google搜索结果中删除的单个页面,实际上您根本不必使用robots.txt方法,您只需将正确的“ robots"元标记添加到各个页面中,并告诉机器人不要来索引或跟踪整个页面上的链接。
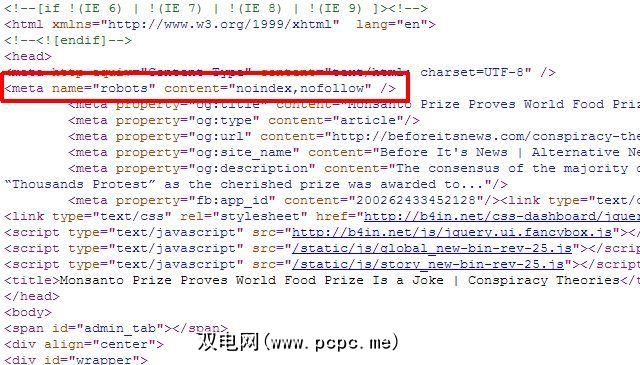
您可以使用上面的“ robots"元数据来阻止机器人对页面进行索引,或者可以明确地告诉Google机器人不要对页面进行索引,因此仅从Google搜索结果中删除,其他搜索机器人仍然可以访问页面内容。
<meta name="googlebot" content="noindex" />
您要如何管理机器人对页面的处理方式以及是否要访问页面,完全取决于您被列出。对于仅几个单独的页面,这可能是更好的方法。要删除内容的整个目录,请使用robots.txt方法。
“删除"内容的想法
这种方式转变了“从内容删除内容"的整个概念。互联网"。从技术上讲,如果您删除了自己指向网站页面的所有链接,并使用robots.txt技术将其从Google搜索和Internet存档中删除,则该页面出于所有意图和目的均已从Internet“删除"。不过,很酷的事情是,如果页面上已有链接,则这些链接仍将起作用,并且您不会为那些访问者触发404错误。
这是一种更加“温和"的方法,可从页面中删除内容Internet,而不会完全破坏您站点的现有链接在Internet上的流行程度。最后,如何管理由搜索引擎收集的内容以及Internet存档取决于您,但是请始终记住,尽管人们对发布在网络上的内容的使用期限有何评价,但实际上这完全在您的控制范围内。
标签: Google Google搜索 SEO 网站设计 网站站长工具